
Non-cryptographic hashing functions: The Infinity Stones of Computer Science – Part 2
In part 1 of this three-parts article we explored some of the powers of non-cryptographic hashing. This time we concentrate on the mastery of Time.

Index
TL;DR summary
- Sets and membership: sets are collections of items; checking membership in large sets can be slow if querying databases directly.
- Problem: high-frequency queries (e.g., checking if a user received a reward) can be expensive and slow due to database access times.
- Bloom filter concept: introduced by Burton Bloom in 1970, it allows set membership checks in constant time using a bit array and multiple non-cryptographic hash functions.
- How it works: each object is hashed to multiple indices in a bit array; if all corresponding bits are 1, the object is likely in the set; if any bit is 0, it is definitely not.
- Trade-off: bloom filters can produce false positives (rare), but never false negatives; the probability of error can be minimized by design.

Introduction: the Time Stone
Sets
I remember the first time I saw Venn Diagrams. I happened to be in elementary school at a time when this overly ambitious and optimistic teacher thought that introducing set theory to a class of 10 year olds was a great idea.
I appreciated the vote of confidence but I have seen brighter looks on wilted celery.
Eventually as an adult studying computer science I persuaded myself that Venn Diagrams are not instructions to draw the Olympics logo but are the graphical representation of different forms of one of the most important concepts in mathematics and logic: the Set.
You can build a set of anything: capers, clowns, transcendental numbers, marmots, jelly babies. You can have sets of sets, the set of all sets, the set of barbers who only shave people who do not shave themselves (who shaves these barbers Dr Russel??). You can even have sets of nothing – the magical empty sets.
In practice (say when coding) Sets imply at least three operations: putting stuff in, getting stuff out and more pertinently for this article, checking if something is already in.
Set membership issues?!?
The operation of checking for Set membership is so basic that it surely must be a done deal, right?
Any SQL database table is basically a set and we can swiftly check if a record is in there with a SELECT statement. Yes in theory, maybe in practice, but we need to get to the database in the first place. We must open a connection with the database, send the query through the wire, wait for the database to compute the result and send it back from whence the query came.
This round-trip is expensive (it takes time) so for production applications we want to keep it to a minimum. “Caching!” I hear you say, while the sky opens up like it does at the start of every Simpsons episode.
Put yourself in the shoes of a developer in a gaming platform company. You’ve got to deal with many users, many games, many rewards, ads etc. Depending on the extent of the platform and its usage, a query like “Did person X get reward Y in game Z today?” could be problematic. If the relevant database tables are large and the joins complex such a high-frequency query could be slow.
Can we really cache the result of this query? Not really, because game state can change any second. And yet, all we are doing is seeking to find out if person X is in the set “got reward Y in game Z today”.
Late Bloom-er
The obvious way to check if X is in set Y is to look at all of Y’s elements in turn until you either find X or you don’t. Clearly as Y gets larger so does the possible number of checks you need to perform.
It was 1970 when a paper from Burton H. Bloom was featured in the Communications of the Association for Computing Machinery (ACM) journal, but the implications of his idea, its applications, implementations and extensions have only started seeing the light of day in the 2000s.
“Space/Time Trade-offs in Hash Coding with Allowable Errors” showed that if you are willing to accept a mistake once in a rare while, you can perform set membership operations at the same constant time complexity regardless of how large your set becomes. Furthermore, with a bit of planning, you can make this margin of error arbitrarily small.
The title suggests that this time-bending feat that only the Time Stone could accomplish, derives from the use of non-cryptographic hashing functions!
A Bloom Filter is a representation of a set requiring only a bit string of length m (this length is selected empirically based on an estimate of the possible number of elements your set could have) and a number k (much, much smaller than m) of hashing functions with the bit string initialised with all 0s.
The idea is to use hashing functions to turn an object X into a set of numbers which are used as indices into the bit string and looking at the values at these indices to find whether X is in Y. To represent that X is in Y you set all the bits in the bit string at the indexes found for X to 1. From then on, given an object Z, we hash it to find its indices. If the value in the bit string at one or more of the indices is 0, the filter says that Z is not in Y. If we find all 1s, the filter says that Z is in Y.
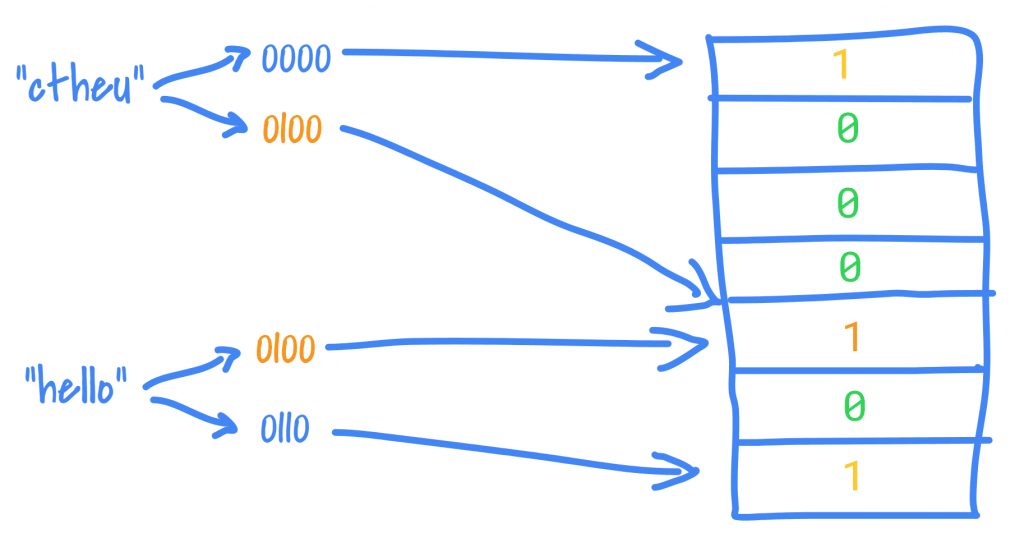
The beauty of this Time Stone is that no matter how big Y becomes, the time complexity of finding set membership this way remains exactly the same – the time it takes to compute the k hashes and look into the bit string.
There is a (small) price to pay for this time-bending…
As we have seen, each object hashes into many indices and depending on the hashing functions and how large k is, different objects may share some of the same indices. At some point, what may happen, is that all of the hashes of a new object Z may end up being shared across several existing objects in the filter. The Bloom Filter is wrongly telling us that Z is in Y, aka a false positive. In other words a negative answer from a Bloom filter is always true whereas a positive answer may be false with a small probability. Thankfully the probability of this happening may be made arbitrarily small.
Bloom filters are used in countless applications and even Google Chrome was using them internally to check URLs against black lists of malicious addresses.
Once again, many great articles, examples, papers and visualisations can be found pertaining to Bloom Filters with some judicious Googling.
Conclusion
Turning objects into a set of indices in Bloom Filter has given us command of Time. Achievement unlocked. Mind and Soul are next!